
树上启发式合并
本文收录于洛谷日报,原文初稿于2018-04-07,经过修改搬运过来。
启发式算法
启发式算法是基于人类的经验和直观感觉,对一些算法的优化。
比较常见的例子是并查集的按秩合并,有带按秩合并的并查集中,合并的代码是这样的:
1 | void merge(int x,int y) |
在这里,对于两个大小不一样的集合,我们将大小小的并到大的,而不是大的连接小的。
为什么呢?这个集合的大小可以认为是集合的高度(在正常情况下),而我们将集合高度小的并到高度大的显然有助于我们找到父亲
让高度小的树成为高度较大的树的子树,这个优化可以称为启发式合并算法。
原理
树上启发式合并( \(\text{dsu on tree}\) ,静态链分治)对于某些树上离线问题可以速度大于等于大部分算法且更易于理解和实现的算法。
考虑下面的问题:
给出一棵树,每个节点有颜色,询问一些子树的颜色数量(颜色可重复)。
提供一个仅供验证算法正确性的模板题树上数颜色,数据纯随机,仅用于验证算法正确性。
对于这种问题解决方式大多是运用大量的数据结构(树套树等),如果可以离线,或询问的量巨大,是不是有更简单的方法?
很容易想到树上莫队,但是树上启发式合并可以在预处理 \(\mathrm{O}(n\log n)\) 的时间复杂度解决这个问题。
既然支持离线,考虑预处理后 \(\mathrm{O}(1)\) 输出答案。
直接暴力预处理的时间复杂度为\(\mathrm{O}(n^2)\),即对每一个子节点进行一次遍历,每次遍历的复杂度显然与\(n\)同阶,有\(n\)个节点,故复杂度为\(O(n^2)\)
可以发现,每个节点的答案是其子树的叠加,考虑利用这个性质处理问题
我们可以先预处理出每个节点子树的size和它的重儿子,重儿子同树链剖分一样,是拥有节点最多子树的儿子,这个过程显然可以 \(\mathrm{O}(n)\) 完成
我们用一个数组 check 表示颜色 \(i\) 有没有出现过,另一个数组 ans 表示他的颜色个数(即答案)
遍历一个节点,我们按以下的步骤进行遍历:
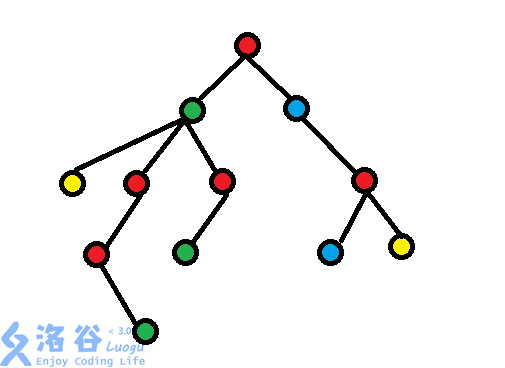
先遍历其非重儿子,获取它的 ans,但不保留遍历后它的check
遍历它的重儿子,保留它的check
再次遍历其非重儿子及其父亲,用重儿子的check对遍历到的节点进行计算,获取整棵子树的ans
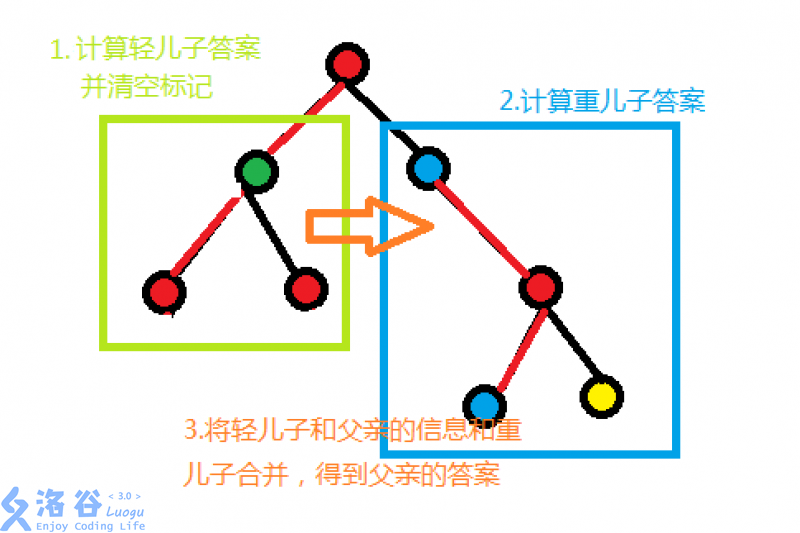
上图是一个例子
这样,对于一个节点,我们遍历了一次重子树,两次非重子树,显然是最划算的。
经过这个过程,我们获得了这个节点的子树的所有 ans
为什么不合并第一步和第三步呢?因为 check 数组不能重复使用,否则空间会太大,需要在 \(O(n)\) 的空间内完成。
显然若一个节点 \(u\) 被遍历了 \(x\) 次,则其重儿子会被遍历 \(x\) 次,轻儿子(如果有的话)会被遍历 \(2x\) 次。
注意除了重儿子,每次遍历完 check 数组要清零。
复杂度
(对于不关心复杂度证明的,可以跳过不看)
我们像树链剖分一样定义重边和轻边(连向重儿子的为重边,其余为轻边)关于重儿子和重边的定义,可以见下图,对于一棵有n个节点的树:
根节点到树上任意节点的轻边数不超过 \(\log n\) 条。我们设根到该节点有x条轻边该节点的子树大小为y,显然轻边连接的子节点的子树大小小于父亲的一半(若大于一半就不是轻边了),则
\[y<\frac{n}{2^x} \]
显然有 \(n>2^x\),所以 $x<n $。
又因为如果一个节点是其父亲的重儿子,则他的子树必定在他的兄弟之中最多,所以任意节点到根的路径上所有重边连接的父节点在计算答案是必定不会遍历到这个节点,所以一个节点的被遍历的次数等于他到根节点路径上的轻边数,所以一个节点的被遍历次数为 \(\log n\) ,总时间复杂度则为 \(\mathrm{O}(n\log n)\),统计答案花费 \(\mathrm{O}(m)\).
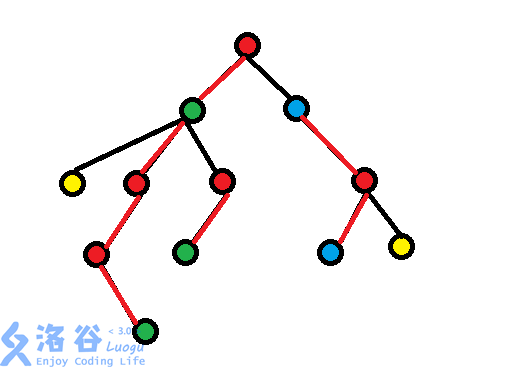
图中标红的即为重边,重边连向的子节点为重儿子
大致代码
1 |
|
使用场合
树上启发式合并普遍运用于求解子树答案的静态问题。只要你能维护一个集合,这个集合支持在一定的时间复杂度 \(f(n)\) 内插入元素和查询集合内所有元素的答案(在数颜色中,就是支持 $(1) $ 的插入和询问颜色个数,即答案),那这个问题就可以在 \(\mathrm{O}(n\log n \times f(n))\) 内计算每个子树的答案。
例如北京理工大学 第 16 届“连山科技”程序设计大赛(November 7, 2022)M题,给定一个树,离线询问子树内互质对个数。发现这个插入一个数并统计当前集合互质对个数是可以用莫反 \(\log n\) 计算的,因此可以树上启发式合并套莫反在 \(\mathrm{O}(n\log^2 n)\) 内解决。
当然也可以求解一些特殊的链上问题,如CF741D,给一棵树,每个节点的权值是'a'到'v'的字母,每次询问要求在一个子树找一条路径,使该路径包含的字符排序后成为回文串。
因为是排列后成为回文串,所以一个字符出现了两次相当于没出现,也就是说,这条路径满足最多有一个字符出现奇数次
正常做法是对每一个节点dfs,每到一个节点就强行枚举所有字母找到和他异或后结果为1的个数<1的路径,再取最长值,这样 \(\mathrm{O}(n^2 \mathrm{log} n)\)的,可以用树上启发式合并优化到 \(\mathrm{O}(n\log^2 n)\) .关于具体做法,可以参考下面的扩展阅读。
练习题
题意翻译:树的节点有颜色,一种颜色占领了一个子树,当且仅当没有其他颜色在这个子树中出现得比它多。求占领每个子树的所有颜色之和。